Where Does Your Data Go?
I've been trying to study System Design for interviews and had the idea to make a visualization of some of the processes I was learning about. I also love the r/explainlikeim5 subreddit and tried to integrate that idea as well.
So I built Where Does Your Data Go? an interactive visualization of what actually happens to your data when you post a photo, send a message, search for something, or stream a video.
The Photo Upload
If you've done system design prep, you've seen the Design Instagram Problem. The standard answer covers media services, object storage, CDN distribution, and fan-out feeds. What it doesn't usually cover is everything that happens before the image even hits your upload API.
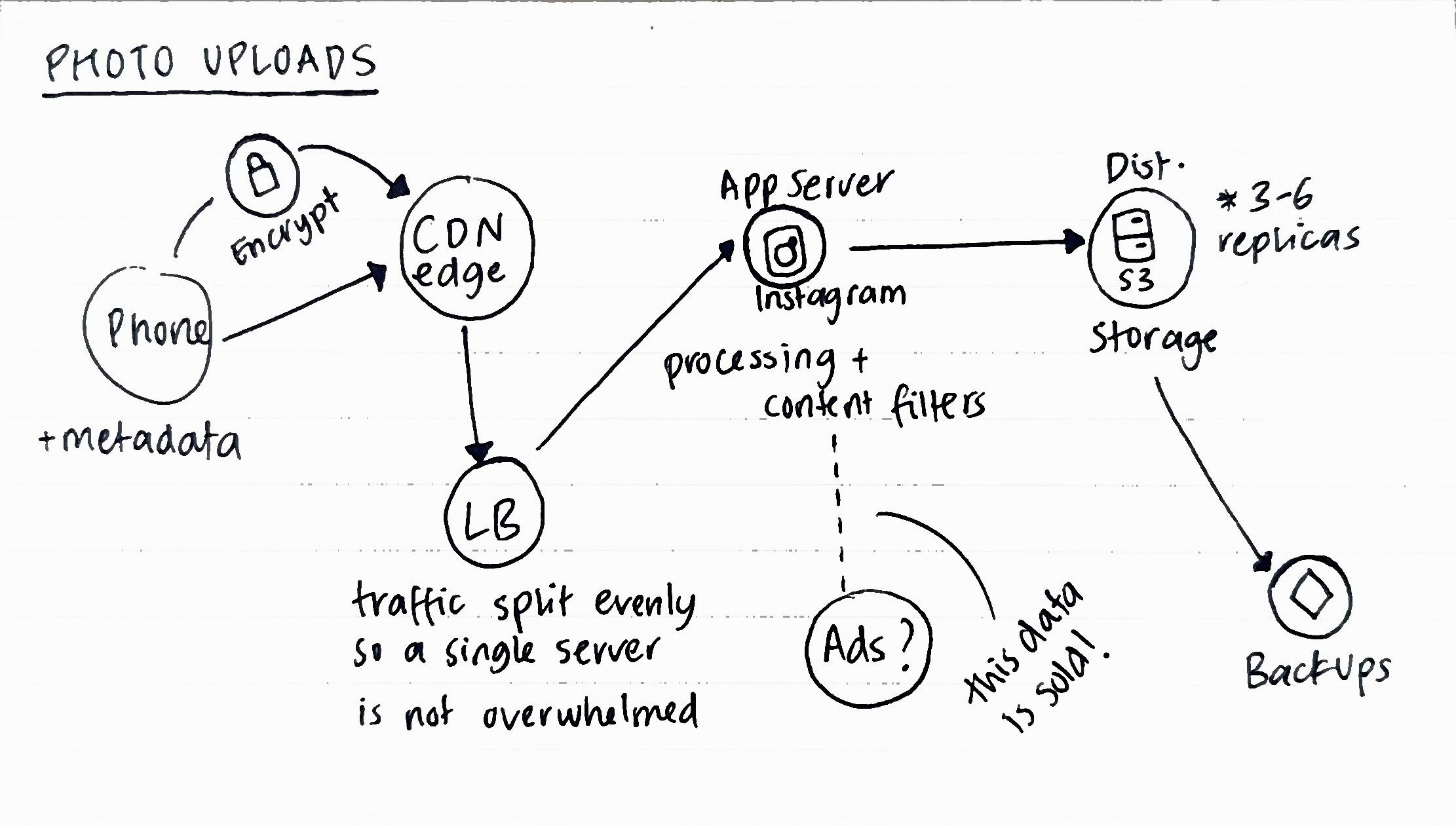
One the client side, before a byte leaves your phone, the image is bundled with metadata: GPS coordinates, device ID, a timestamp, facial embeddings for anyone in the frame, device model, etc.
Once the upload fires, it hits a CDN edge node first, not your origin server. There are about 300+ edge locations globally. This means that the photo lands on servers in multiple countries first. After this, a Load Balancer routes to application servers, which run AI classification (these are usually content filters for Instagram that perform object detection, brand detection, nudity flagging, etc) on every upload.
Storage is where it gets pretty interesting from an architecture standpoint. Platforms typically maintain 3-6 replicas across various geographic regions for backups and redundancy. The separation of reads and writes is a common SD pattern. Uploads are slow and disk-bound, feeds are read-heavy and cache-optimized. So they usually live on different server pools. What this also means is that "deleted" photos aren't immediately erased. They're marked for deletion and can persist in backup storage for 30-90 days.
Sending A Message
The architecture of messaging apps is a common SD question, usually about message queues, delivery guarantees, fan-out to multiple devices.
End-to-end encryption protects message content. Apps like Signal and Whatsapp use the Signal E2E protocol. Most other platforms tho like Instagram DMs, default Messenger don't use E2E at all server-side. But even E2E encryption does not protect metadata.
Who you message, when, how often, for how long - all of it is logged even if they're not reading the actual words. Researchers have argued that this metadata can be as revealing as the content itself.
There's also the legal layer. The CLOUD Act (2018) lets US federal law enforcement compel US-based tech companies to hand over data stored on servers anywhere in the world. Your messages routed through a server in Germany aren't shielded from a US-warrant just because of geography.
Search Engines

The search flow is an interesting architecture to study. Most SD problems walk through DNS resolution -> CDN cache -> search index. My favourite resource for this is the GeeksforGeeks CDN Explainer.
What I always wondered about and is the autocomplete when you start typing a query into your search engine of choice. Pretty cool if you think about it. After 1-3 keystrokes, your partial query is already in flight to the server. At scale, Google processes around 8.5 billion searches per day, each one logs your IP address, device fingerprint, location and if you have search history turned on then all of that as well.
Yes results are retrieved based on an index, but they're also re-ranked against a model of you. Your past searches, inferred job/income, location, browsing patterns, etc. I've been looking into this a bit more so once I understand it better I'll try to come back and update this.
Video Streaming
Genuinely the architecture of video streaming blows my mind. The system design of Netflix or Youtube at scale is one of the most impressive and elegant distributed systems problem I've encountered.
When you press play, you're not downloading a video file (that would take too long). You're requesting tiny chunks, typically 2-6 seconds each. Served via HLS or MPEG-DASH. The player dowloads a manifest file first that lists all the available quality renditions and their segment URLS. It then continuously measures your bandwidth and switches quality levels at segment boundaries, without having to rebuffer. This is called Adaptive bitrate (ABR) streaming.
Every video is pre-encoded into roughly 12 quality levels (240p to 4K), split into those segments per level, and pushed to CDN edge nodes globally. Netflix pioneered per-title encoding. Rather than applying the same bitrate ladder to every video, they analyze visual complexity per scene and allocate bitrate accordingly. Insane! I know. A slow dialogue scene and a fast action sequence get different treatment. The result was 20–30% bandwidth savings with no perceptible quality loss.
The tradeoff for all of this smoothness is surveillance-grade behavioral logging. The platform knows exactly where you paused, what you rewound, what you skipped, and whether you finished. That data feeds the recommendation engine and, on ad-supported platforms, it gets packaged into interest segments ("true crime fan," "new parent," "fitness enthusiast") and sold to advertisers across the ecosystem.
Why I Built This
I'm trying to understand the foundations of these concepts really solidly and this felt like a good way to do that. I used AI to render all the frontend styling so I could make this project over the weekend after lots of days researching and learning the concepts.
The "what really happens" toggle is the design decision that I'm super pleased with :D. Flipping the switch to see the same infrastructure but from a data and surveillance standpoint is fun, don't you think?
I have so much more to learn and feel like I'm just skimming the top of a lot of these complicated concepts. So you have advice or tips for me as a junior engineer, I'D LOVE TO HEAR IT PLS.